
When dealing with security, I try to stick to tried and trusted practices since security is such a delicate topic. I'm not making any claims about the scheme I describe here. I'm only opening up a discussion. One of the security issues I'd like to address is cross site request forgery (CSRF).

A CSRF is an attack where one site directs a user to another site in such a way that the second site thinks the request originated on a page from itself. To illustrate, suppose I put a link here with its href like so: http://www.example.com/?c=DeleteAccount. If example.com isn't doing the right thing, and you click that link, then your account at example.com might be accidentally deleted. And the fact that example.com password protects your account won't necessarily help here if you're logged in in another window when you click the link. example.com has failed to adequately protect you.
So let me propose a scheme to address this vulnerability, and you can tell me what you think. Suppose example.com were to sign the request strings for the urls for its sensitive actions. That is, suppose instead of allowing the above url, it were to use this one: http://www.example.com/?c=DeleteAccount&k=SomeSig. Here SomeSig should be a signature of c=DeleteAccount (or perhaps the whole url).

Now a clever attacker would just have to get an account with example.com, find the delete account url, and grab the url (including the unforgeable signature). The problem has not changed at all. The attacker can just craft a forum post and wait for users to delete their accounts (or transfer funds to him/herself).
So let's ditch the signature and add an expiry to the url: http://www.example.com/?c=DeleteAccount&e=Soon. Here Soon is a timestamp after which you'd like to invalidate the url. Many sites log users out after ten or fifteen minutes, so pick something good inside of that. If you get an expired url, you can always have a warning that the url has expired and ask the user to click a new (similar, but updated) url. The idea is to force the user to understand what is about to happen.
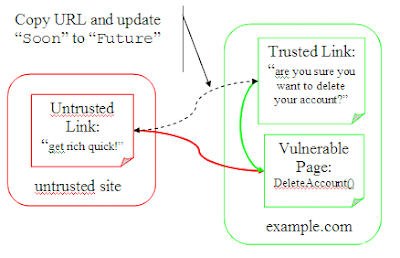
Now if the attacker copies the url into a forum post the link will only be valid for some short time. Of course, the attacker can just update Soon to EndOfTime and we're back at square one.
But if we combine these two approaches (and add a nonce to make cracking the signature more difficult) we're a little bit better off: http://www.example.com/?c=DeleteAccount&e=Soon&n=Nonce&k=SomeSig. Now we're signing the command and the expiry so that neither can be forged.

Of course, attackers can just keep going back for updated urls (or have a bot do it for them). But we've at least we've reduced the problem (unlike the previous two attempts).
The issue here is that we're continuing to trust an untrusted source. We have a trusted url (which can't be forged), but it only says, "delete account within my expiry". But what account should be deleted? We're assuming that we should delete the account of the user currently logged in. That makes some sense (we might not want to allow users to delete arbitrary accounts). But our unforgeable url makes no claims about which account to delete.
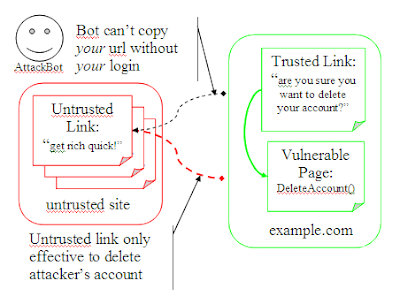
So let's have the url assert that too: http://www.example.com/?c=DeleteAccount&e=Soon&n=Nonce&u=UserID&k=SomeSig. Now when you get this url, check that it's signed correctly, that it hasn't expired, and that the current user matches the user the url was created for. Our url asserts all of these things. And we can trust that all of these things are true, since the url comes with our own signature.
Again, I'm not making any claims that this "solves" the problem. This addresses some aspects of the problem. Feel free to correct any mistakes I've made; that's the point of this blog post. For instance, if an attacker does obtain this "unforgeable url", he or she can still embed it in a blog post and persuade a user to click the link within the expiry. At that point someone still loses an account. Ultimately a CSRF is still possible under this scheme. And there are probably some other weaknesses to the scheme as well. And I'd love to hear about them.
Anyway, I like this scheme so far. Mostly I'd like to use this scheme for 301 redirects after a form post-back with a confirmation: I'm trying to protect against forging the confirmation dialog. But the initial form post-back is just as vulnerable and should be protected also. What do you think?









